PDC 2008, Day #3, Session #4, 1 hr 15 mins
Pablo Castro
I attended a second session with Pablo Castro (the previous one was the session on Azure Tables). This session focused on a future capability in ADO.NET Data Services that would allow taking data services “offline” and then occasionally synching them with the online data.
Background – Astoria
ADO.NET Data Services was recently released as part of the .NET Framework 3.5 SP1 release. It was formerly known as project “Astoria”.
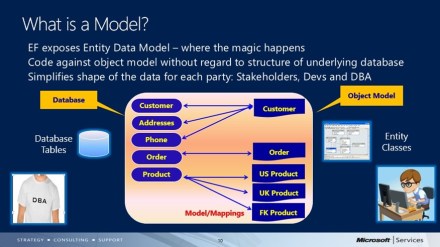
The idea of ADO.NET Data Services is to allow creating a data service that lives on the web. Your data source can be anything—a SQL Server database, third-party database, or some local data store. You wrap your data source using the Entity Data Model (EDM) and ADO.NET Data Services Runtime. Your data is now available over the web using standard HTTP protocols.
Once you have a data service that is exposed on the web, you can access it from any client. Because the service is exposed using HTTP/REST protocols, you can access your data using simple URIs. By using URIs, you are able to create/read/update/delete your data (POST/GET/PUT/DELETE in REST terms).
Because we can access the data using HTTP, our client is not limited to a .NET application, but can be any software that knows about the web and HTTP. So we can consume our data from Javascript, Ruby, or whatever. And the client could be a web-based application or a thick client somewhere that has access to the web.
If your client is a .NET client, you can use the ADO.NET Data Services classes in the .NET Framework to access your data, rather than having to build up the underlying URIs. You can also use LINQ.
So that’s the basic idea of using ADO.NET Data Services and EDM to create a data service. For more info, see:
The Data Synchronization Landscape
Many of the technologies that made an appearance at PDC 2008 make heavy use of data synchronization. Data synchronization is available to Azure cloud services or to Live Mesh applications.
The underlying engine that handles data synchronization is the Microsoft Sync Framework. The Sync Framework is a synchronization platform that allows creating sync providers, sitting on top of data that needs to be synchronized, as well as sync consumers—clients that consume that data.
The basic idea with sync is that you have multiple copies of your data in different physical locations and local clients that make use of that data. Your client would work with its own local copy of the data and then the Sync Framework would ensure that the data is synched up with all of the other copies of the data.
What’s New
This session talked about an effort to add support in ADO.NET Data Services for offline copies of your Astoria-served data, using the Sync Framework to do data synchronization.
Here are the basic pieces (I’m too lazy to draw a picture). This is just one possible scenario, where you want to have an application that runs locally and makes use of a locally cached copy of your data, which exists in a database somewhere:
- Data mainly “lives” in a SQL Server database. Assume that the database itself is not exposed to the web
- You’ve created a data service using ADO.NET Data Services and EDM that exposes your SQL Server Data to the web using a basic REST-based protocol. You can now do standard Create/Read/Update/Delete operations through this interface
- You might have a web application running somewhere that consumes this data. E.g. A Web 2.0 site built using Silverlight 2, that allows viewing/modifying the data. Note that the web server does not have a copy of your data, but goes directly to the data service to read/write its data.
- Now you create a thick client that also wants to read/write your data. E.g. A WPF application. To start with, you assume that you have a live internet connection and you configure the application to read/write data directly from/to your data service
At this point, you have something that you could build today, with the tools in the .NET Framework 3.5 SP1. You have your data out “in the cloud” and you’ve provided both rich and thin clients that can access the data.
Note: If you were smart, you would have reused lots of code between the thin (Silverlight 2) and thick (WPF) clients. Doing this gives your users the most consistent GUI between online and offline versions.
Now comes the new stuff. Let’s say that you have cases when you want your thick WPC client to be able to work even though the Internet connection is not present. Reasons for doing this include:
- You’re working on a laptop, somewhere where you don’t have an Internet connection (e.g. airplane)
- You want the application to be more reliable—i.e. app is still usable even if the connection disappears from time to time
- You’d like the application to be slightly better performing. As it stands, the performance depends on network bandwidth. (The “lunchtime slowdown” phenomenon).
Enter Astoria Offline. This is the set of extensions to Astoria that Pablo described, which is currently not available, but planned to be in Alpha by the end of the year.
With Astoria Offline, the idea is that you get a local cache of your data on the client PC where you’re running your thick client. Then what happens is the following:
- Your thick (WPF) application works directly with the offline copy of the data
- Performance is improved
- Much more reliable—the data is always there
- You initiate synchronization (or set it up from time to time) to synch data back to the online copy
This synchronization is accomplished using the new Astoria Offline components. When you do synchronize, the synchronization is two-ways, which means that you update both copies with any changes that have occurred since you last synched:
- All data created locally is copied up to the online store
- Data created online is copied down
- Changes are reconciled—two-way
- Deletions are reconciled—two-way
Pablo did a basic demo of this scenario and it worked just as advertised. He showed that the client worked with the local copy of the data and that everything synched properly. He also showed off some early tooling in Visual Studio that will automate much of the configuration that is required for all of this to work.
Interestingly, it looked like in Pablo’s example, the local copy of the data was stored in SQL Server Express. This was a good match, because the “in the cloud” data was stored in SQL Server.
How Did They Do It?
Jump back to the description of the Microsoft Sync Framework. Astoria Offline is using the sync framework to do all of the underlying synchronization. They’ve written a sync provider that knows about the entity data model and interfaces between EDM and the sync framework.
Extensibility Points
I’m a little fuzzier on this area, but I think I have a general sense of what can be done.
Note that the Sync Framework itself is extensible—you can write your own sync providers, providing synchronized access to any data store that you care to support. Once you do this, you get 2-way (or more) synchronization between your islands of custom data.
But if I understood Pablo correctly, it sounds like you could do this a bit differently with Astoria Offline in place. It seems like you could pump your custom data from the Entity Framework, by building a custom data source so that the EDM can see your data. (EntityFrameworkSyncProvider fits in here somewhere). I’m guessing that once you serve up your data in a relational manner to the EDM, you can then synch it using the Astoria Offline mechanisms. Fantastic stuff!
Going Beyond Two Nodes
One could imagine going beyond just an online data source and an offline copy. You could easily imagine topologies that had many different copies of the data, in various places, all being synched up from time to time.
Other Stuff
Pablo talked about some of the other issues that you need to think about. Conflict detection and resolution is a big one. What if two clients both update the same piece of data at the same time? Classic synchronization issue.
The basic things to know about conflicts, in Astoria Offline, are:
- Sync Framework provides a rich model for detecting/resolving conflicts, under the covers
- Astoria Offline framework will detect conflicts
- The application provides “resolution handlers” to dictate how to resolve the conflict
- Could be locally—e.g. ask the user what to do
- Or online—automatic policies
Pablo also talked briefly about the idea of Incremental Synchronization. The idea is that you might want to synch things a little bit at a time, in a batch-type environment.
There was a lot more stuff here, and a lot to learn. Much of the concepts just bubble up from the Sync Framework.
Takeaways
Astoria Offline is potentially game-changing. In my opinion, of the new technologies presented at PDC 2008, Astoria Offline is the one most likely to change the landscape. In the past, vendors have generally had to pick between working with live data or local data. Now they can do both.
In the past, the online vs. offline data choice was driven by whether you needed to share the data across multiple users. So the only apps that went with offline data were the ones that didn’t need to share their data. What’s interesting about Astoria Offline is that these apps/scenarios can now use this solution to leave their data essentially local, but make the data more mobile, across devices. Imagine an application that just stores local data that only it consumes. But now if you want to run that app on multiple machines, you have to manually copy the data—or move it to a share seen by both devices. With Astoria Offline, you can set up a sync to an online location that each device synchs to, as needed. So you can just move from device to device and your data will just follow you. So you can imagine that this makes it much easier to move apps out to mobile devices.
This vision is very similar to what Live Mesh and Live Services promise. But the difference is that here you don’t need to subscribe to your app and its data living in the MS Live space. Your data can be in whatever format you like, and nobody needs to sign up with MS Live.
When Can I Get It?
Pablo mentioned a basic timeline:
- Early Alpha by the end of the year
- CTPs later, i.e. next year
Resources
In addition to the links I listed above, you might also check out: