Last time I posted a list of the most popular file/folder backup tools. This time, I’ll look at Windows backup tools that fall into the categories: drive imaging, file/folder synchronization, and online storage.
NOTE: This post is just a survey of available tools, rather than a review. I’ve used some, but not all, of the tools listed.
Backing up your files and folders should be just a part of your overall backup strategy, but not the entire strategy. A complete approach would likely include some use of full system backups (imaging), as well as synchronization and online backups.
The tools that I mentioned last time are good for:
- Automating your backups
- Getting your files backed up to another PC, via network device
- Backing files up efficiently, by doing a combination of full/incremental backups
- Creating “snapshots” of files at a specific point in time
What these traditional tools are not necessarily as good at doing is:
- Getting your files backed up to an off-site location
- Sharing files/folders with other devices
- Allowing you to browse files in original directory structure
- Backing up your Windows system files
- Backing up and restoring an entire PC
The tools in these other categories (imaging, synchronization, and online backup) address some of the shortcomings of traditional file/folder backup tools.
Drive Imaging Tools
In addition to periodically backing up your data files, you should consider doing a full disk backup, or image backup. Traditional file/folder backup tools typically don’t support backing up an entire disk or partition.
For drive imaging software, I took a brief look at the following products:
- Acronis True Image
- Norton Ghost
- Image for Windows
- Paragon Drive Backup
- ShadowProtect
- DriveImage XML
- NTI Drive Backup
These products are all very similar, but there are a few differences. My list of available features is based on the documentation on each product’s web site.
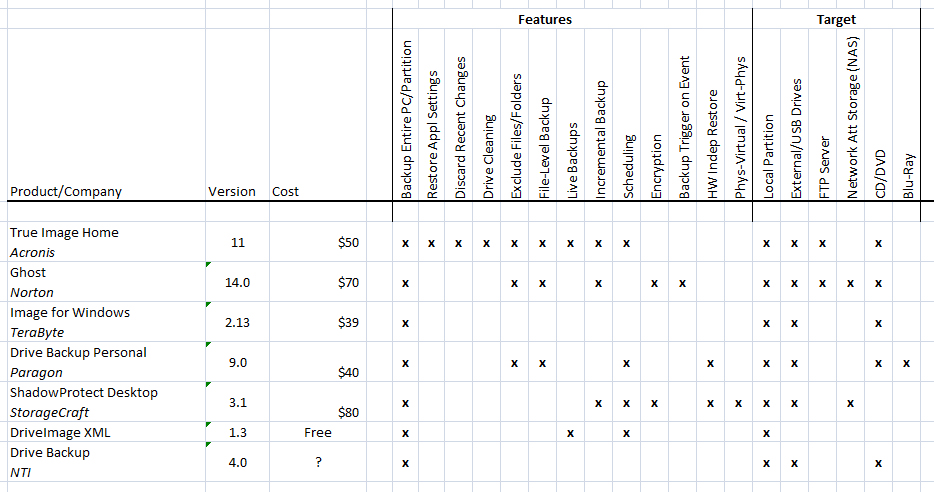
Drive Imaging Tools
Synchronization Tools
The goal of synchronization tools isn’t to create a backup of a directory, but to create a copy of that directory on other devices. Typically, one PC shares one or more directories, making them visible to the tool or service. Other devices subscribe to the shared folder and then replicate the contents locally.
What makes synchronization tools so powerful is their ability to do continuous/live updates. When someone changes a file in a shared folder, that change is replicated across all of the subscribing PCs immediately.
This gives us the benefits of both shared network drives and remote backups—users on other machines have access to the data at all times and can edit it from their machine. And the data is also backed up, in that it’s stored in multiple locations.
Desirable features to look for in file synchronization tools include things like:
- Continuous Updates: no need to synch manually
- Multiple Subscribers: synchronize across multiple devices
- 2-Way Synchronization: users can change files in any location
- Share Across HTTP: PCs don’t need to be on LAN, but can share via Internet
- Encryption: data transferred via HTTP in secure manner
- Backup to Cloud: store copy of synched files online
The chart below includes the following synchronization tools and a list of features:
- BounceBack Pro
- SyncBackSE
- Allway Sync
- Windows Sync (Vista)
- Microsoft LiveMesh
- Windows Live FolderShare
- SugarSync
- Syncplicity
- Dropbox
- Microsoft SyncToy

Synchronization Tools
Traditional synchronization tools worked only with devices that were directly networked on a LAN. But modern synchronization tools are more commonly delivered as a web-based services that synchronize machines via HTTP. A PC shares a folder to the service, causing the files to get replicated in “the cloud”. And then other devices can in turn sync to the same folder, allowing the files to get downloaded to the subscribing device.
This “cloud” approach allows doing online backups in addition to synchronizing files across devices. This is a nice blending of traditional synchronization tools with online backup tools.
Microsoft’s new LiveMesh platform offers maybe the best combination of features spanning both synchronization and online backup. For each folder added to the mesh, the user can choose exactly which devices to synch the contents to—including both physical devices in the mesh, as well as the online storage area. This allows doing peer-to-peer synchronization for some data, and online backup for other data.
There are many more network-only synchronization tools available than I list in this chart. Given the power of the newer tools that also provide online backup, these older tools are becoming less popular.
Online Backup Tools / Services
There are also services that offer pure online backup of data, rather than both synchronization and backup. The chart below lists some of the more common ones, including:
- Carbonite
- Dell Datasafe
- Diino
- Drop.io
- IDrive
- JungleDisk / Amazon S3
- LiveMesh
- Mozy
- SpareBackup
- Windows Live FolderShare
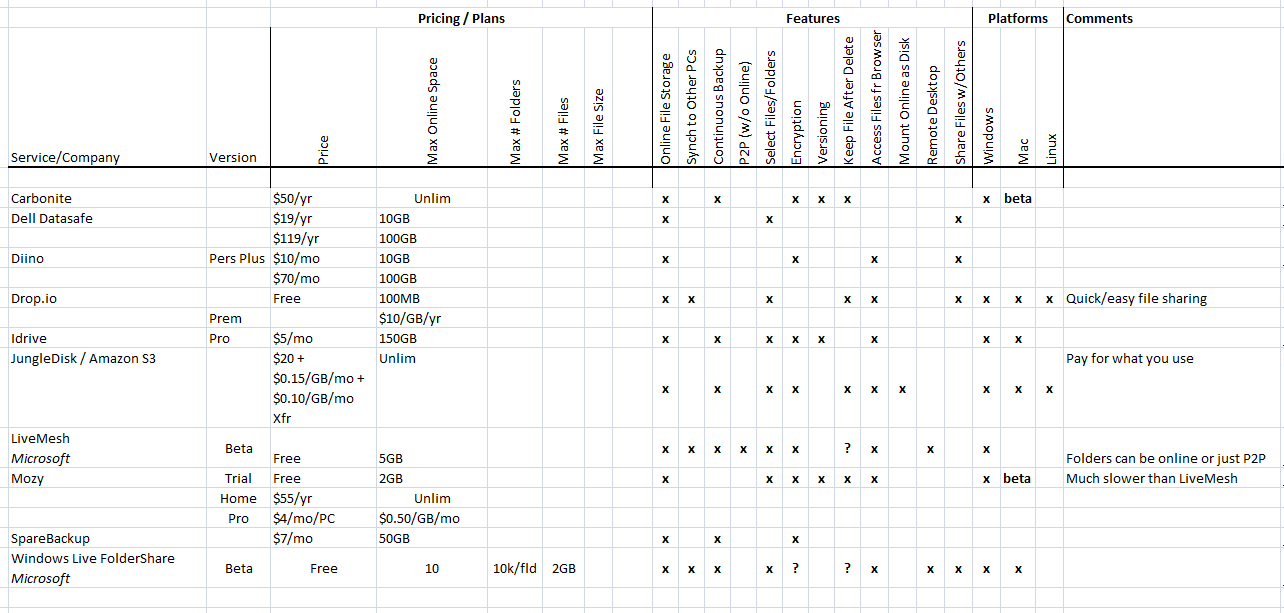
Online Backup Services
With easy access to highspeed Internet access these days, it’s clear that online backup, rather than network-only backup, is the preferred choice for most people. And with storage prices continuing to drop, these services are becoming affordable, even for storing huge amounts of data, like photos & videos.
The future for these products is likely something like the LiveMesh model. This approach (once LiveMesh provides larger amounts of online storage) is:
- Continuous online backups
- Automatic synchronizing of data to multiple devices
- Ability to do both synchronizing (exact mirrors) and archival (backup at a point in time)
Next Time
At the moment, I’m personally using a combination of LiveMesh and JungleDisk for my backups. Next time, I’ll describe how I use these tools.